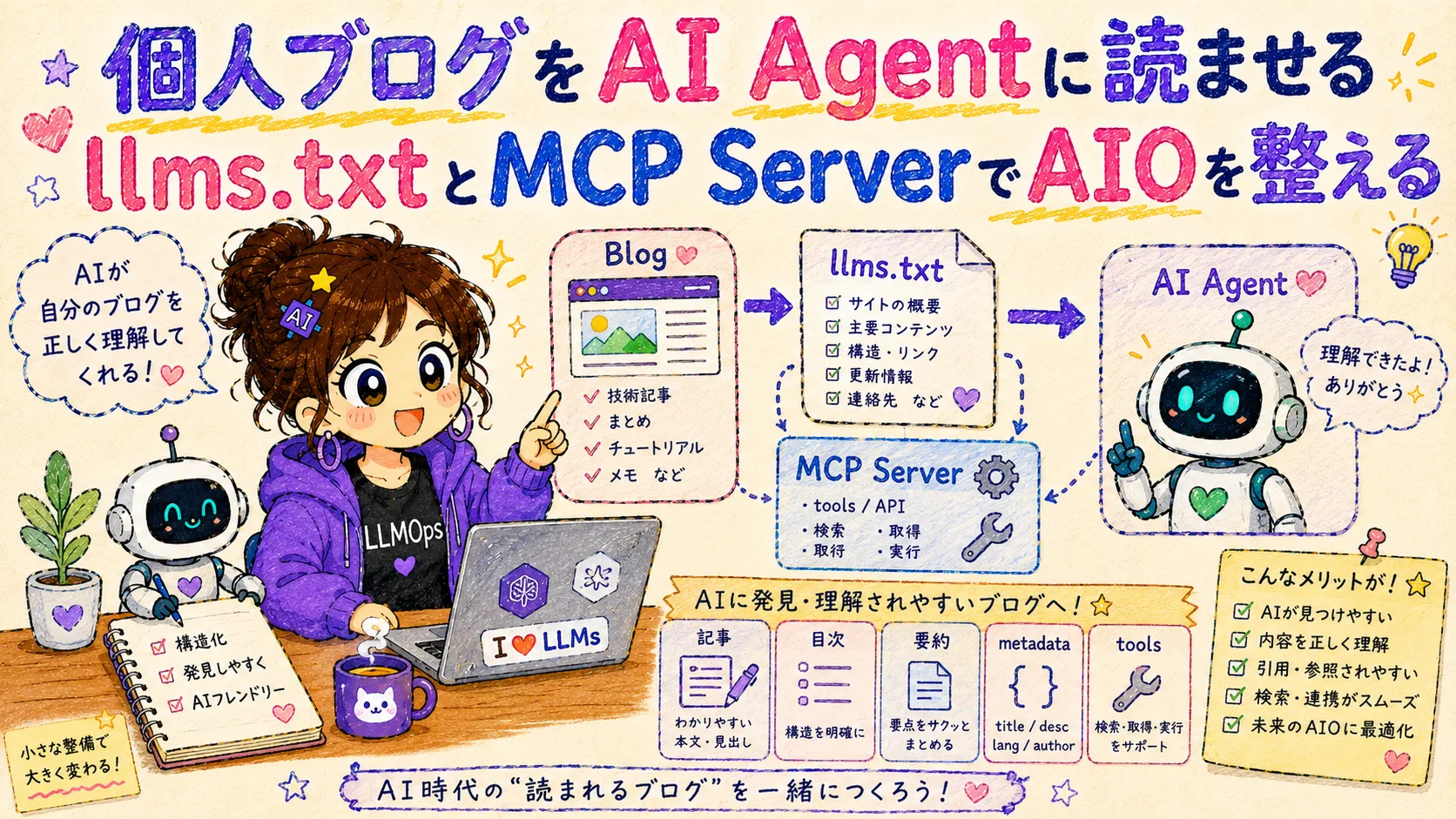
個人ブログをAI Agentに読ませる llms.txtとMCP ServerでAIOを整える
PerplexityやChatGPTが検索の代わりになる中、個人ブログをAI Agentからも発見可能にするAIO(AI最適化)の実装。llms.txt、JSON API、MCP Serverの3層設計と、46本規模での採用判断基準。
最近、自分が情報を探すときの入り口が変わってきたことに気づいた。技術的な疑問を調べるとき、まずGoogleを開くことが減り、PerplexityやClaude Code、ChatGPTに問いかけることが増えた。これは個人的な癖ではなく、検索の入り口そのものが「検索エンジン」から「AI Agent」へ移りつつある証左だろう。
そこで自問した。自分のブログは、AI Agentからどう見えているのか。
人間向けSEOは整った。AI向けはまだ
このブログは2024年からAstroで構築し、日本語と英語の両言語体制で46本の記事を公開している。人間向けのSEO基盤は一通り整えたつもりだった。
全文検索にはPagefindを導入し、日本語と英語の92ページをインデックスしている。多言語対応ではhreflangとcanonical、JSON-LDのBreadcrumbList、OGPを設定し、Googleが正しくインデックスできる状態にしている。記事内には目次、前後の記事ナビゲーション、コードブロックのコピーボタンも備えている。
しかし、これらはあくまで「人間がブラウザで読むことを前提」とした最適化だ。AI Agentがこのサイトにアクセスした場合、46本の記事は「断片的なHTMLの山」にしか見えない。Pagefindの検索UIは人間が使うもので、AIにはプログラム的なインターフェースが必要だ。
AI Agentは、サイトの構造を素早く把握し、「どの記事に何が書いてあるか」を機械的に理解したい。それには、HTMLよりも前に、構造化された概要と、プログラムで取得できるメタデータが必要になる。
AIO(AI Optimization)の3層設計
この課題に対し、3層のAIO(AI Optimization)を設計した。
- Layer 1: llms.txt — AI向けのサイト概要ファイル
- Layer 2: JSON API — 記事メタデータの機械可読な取得口
- Layer 3: MCP Server — AI Agentからの標準化されたツール呼び出し
この3層は、それぞれ「概要を伝える」「データを提供する」「ツールとして動作する」という異なる粒度を担う。どれも必須ではないが、Layer 1と2は最小限の実装コストで高い効果が見込める。
Layer 1: llms.txt の導入判断
llms.txtは2024年から急速に普及しつつある、AI向けサイト概要ファイルの標準仕様だ。llmstxt.orgの定義に従い、サイト名、概要、主要セクション、連絡先をプレーンテキストで記載する。
実装にあたり、最初に迷ったのは「どこまで機械的にするか」という点だった。whatwg/fetchのように厳密なフォーマットに従う案もあるが、llms.txtの本質は「人間が読めるプレーンテキスト」にある。AIが読みやすいことと、人間がメンテナンスしやすいことは両立すべきだと判断し、マークダウン風のテキストフォーマットを採用した。
実装は src/pages/llms.txt.ts にAstroのエンドポイントとして配置した。独立したスクリプトではなく、Astroビルドの一部にした理由は、ビルド時に最新の記事リストとカテゴリ数を自動的に取得できるからだ。手動でテキストを更新する運用は、記事が増えるたびに破綻する。
内容には以下を含めた。
- サイト名と概要(日本語・英語両方)
- 主要カテゴリと記事数(13カテゴリ)
- 人気記事上位15本のタイトルとURL
- シリーズ一覧(Langfuse朝ブリーフィング、Vercel Eve入門、Flue実践入門)
- Markdownエクスポートの案内
- ライセンスと連絡先
正直、ここまで含める必要があるのか最初は迷った。でも「AIがこのサイトの範囲を正しく理解する」という目的を考えると、多すぎるよりは少なすぎる方が問題だと結論づけた。
Layer 2: JSON API の設計判断
Layer 2では、全46本の記事メタデータをJSON形式で公開する /api/articles.json を作成した。
設計で最初に立てた判断は「GraphQLは必要か」という点だった。結論として、46本規模ではGraphQLは過剰だ。RESTの全件返却で十分であり、むしろシンプルさがメンテナンス性につながる。将来的に記事数が500本を超えた段階で、?limit= や ?category= といったクエリパラメータを追加すればよい。
JSONの構造には、日本語記事主軸で英語版をペアリングする形を取った。日英の紐付けには translationKey(なければ permalink)を使用し、同一記事の異言語版を正しく対応付けている。
{
"title": "APIで最小ループを組むと...",
"titleEn": "When You Build a Minimal API Loop...",
"slug": "llm-loop-engineering-minimal-api",
"url": "https://llm-lab.dev/posts/llm-loop-engineering-minimal-api/",
"urlEn": "https://llm-lab.dev/en/posts/llm-loop-engineering-minimal-api/",
"date": "2026-06-28",
"category": "設計",
"categoryEn": "Design",
"tags": ["llmops", "eval", "loop-engineering", "aidd"],
"description": "...",
"series": null,
"seriesOrder": null
}CORSヘッダーには Access-Control-Allow-Origin: * を設定した。公開データであり、認証が不要な情報源なので、クロスオリジンからのアクセスを制限する理由はない。
Layer 3: MCP Server の設計
Layer 3は、今回は実装ではなく設計段階までとした。Model Context Protocol(MCP)は、Anthropicが提唱するAI Agentと外部ツールを連携する標準プロトコルだ。
MCPには2つのトランスポート層が存在する。stdio(標準入出力、ローカル接続用)とSSE over HTTP(Server-Sent Events、リモート接続用)だ。ブログの記事情報を公開APIとして提供する以上、ローカル接続に閉じるstdioではなく、どこからでもアクセス可能なSSE over HTTPを採用すべきと判断した。
インフラにはCloudflare Workersを推奨とした。サイトと同じCloudflareエコシステムで運用でき、エッジ配置による低レイテンシ、無料枠(100,000リクエスト/日)という点が理由だ。46本の記事をインメモリで検索する場合、レイテンシは1ミリ秒未満に収まる。
設計したツールは5つだ。
search_articles: キーワード・カテゴリ・タグ・シリーズ・言語での検索get_article: slug指定での個別記事メタデータ取得list_categories: カテゴリ一覧(日本語/英語ラベル付き)list_tags: タグ一覧(記事数付き)list_series: シリーズ一覧(順序付き記事リスト付き)
これらの詳細設計は docs/mcp-design.md に文書化し、今後の実装に備えた。
示唆: 個人ブログ運営者がやるべきAIO
今回の実装を通じて得た、再利用できる判断基準を3つ挙げる。
第一に、llms.txtは「最小工数・高インパクト」だ。1ファイル、約100行のコードで、AI Agentがサイト全体を理解する入口を整備できる。個人ブログ運営者なら、まずこれをやるべきだ。
第二に、JSON APIは「将来の自動化の土台」になる。今は単なるメタデータ一覧だが、将来的にニュースレターの自動生成、SNS投稿の自動化、MCP Serverのデータソースとして再利用できる。46本規模でも、構造化しておく価値はある。
第三に、MCP Serverは「記事をツール化する」発想の転換だ。これまでは「人間に読ませる」ことを前提にコンテンツを設計していた。MCPを経由すると、「AI Agentがツールとして呼び出す知識源」として記事が機能する。コンテンツの価値を、読者数だけでなく「Agentからの呼び出し回数」でも測る日が来るかもしれない。
次の段階
AIOの基盤が整った次の段階で考えているのは、インメモリ検索の限界突破だ。46本なら問題ないが、500本を超えるとCloudflare Workersのインメモリアプローチではパフォーマンスが劣化する。そこでCloudflare Vectorizeへの移行を検討し、セマンティック検索を可能にする予定だ。
また、インタラクティブデモも計画している。例えば、ブログのメタデータを基にClaude Desktop用のMCP Server設定を生成するツールを /tools/ 配下に公開すれば、読者が「読む」だけでなく「触って理解する」体験ができる。
AI Agentが検索のデフォルトになりつつある今、個人ブログも人間向けの見た目だけでなく、機械向けの構造化を整える必要がある。それはSEOの延長線上にあるものではなく、コンテンツの存在そのものを「発見可能」にする、新しい層の最適化だ。