ClickHouse × Claude MCPで実現する自然言語データ分析 — SQLを書かない時代は来るのか
ClickHouse MCPを利用して、Claude DesktopからClickHouseを自然言語で操作する環境を構築します。

はじめに
データ分析の世界では、長らくSQLが共通言語として使われてきました。
データベースから必要な情報を取り出し、集計し、異常を検知する。そのためには、分析者自身がテーブル構造を理解し、適切なSQLを書けることが前提でした。
一方で、生成AIの進化によって、この前提は大きく変わり始めています。
「昨日のエラー数をサービス別に集計して」 「直近1時間で急増しているリクエストを教えて」 「レスポンス時間が通常より高いエンドポイントを調査して」
このような自然言語の指示から、AIが適切なSQLを生成し、データベースを検索し、その結果を解釈して返す仕組みが現実的になりつつあります。
その中心にある技術の一つが、MCP(Model Context Protocol)です。
MCPを利用すると、ClaudeなどのLLMは単なる文章生成ツールではなく、外部システムを操作するエージェントとして振る舞えます。
本記事では、ClickHouse MCPを利用して、Claude DesktopからClickHouseを自然言語で操作する環境を構築します。
単なるセットアップ手順の紹介ではありません。実際にログデータを投入し、自然言語によるクエリ生成の精度、失敗するケース、実運用する際のセキュリティ上の課題まで検証します。
結論から言えば、「SQLを書く必要が完全になくなる」わけではありません。しかし、データ探索や障害調査の初動は大きく変わる可能性があります。
なぜ今、データベースにAIを接続するのか
従来、データ分析には大きなボトルネックがありました。
それは「知りたいこと」と「SQL」という形式の間に変換作業が存在することです。
例えば、サービス運用者が「昨日から急に増えているエラーはないか」と考えたとします。
これをSQLに変換する場合、以下のような作業が必要になります。
- どのテーブルにログが保存されているか確認する
- エラーを示すカラムを特定する
- 集計単位を決める
- GROUP BYやWHERE句を書く
- 結果から原因候補を推測する
熟練したデータエンジニアであれば数分でできます。
しかし、プロダクトマネージャー、SRE、カスタマーサポートなど、必ずしもSQLを日常的に書かない職種にとっては高い壁になります。
ここにLLMを挟むことで、意図は自然言語のまま、データベース操作だけをAIに変換させることができます。
重要なのは、これは「SQLを置き換える技術」ではないという点です。
むしろ、SQLという強力な言語を、より多くの人が利用できるインターフェースへ変換する技術と考えるべきでしょう。
MCPとは何か
MCP(Model Context Protocol)は、LLMが外部ツールやデータソースと安全に接続するための標準プロトコルです。
これまでLLMに外部システムを操作させる場合、ツールごとに独自のAPI連携を実装する必要がありました。
例えば、
- GitHubを操作する
- データベースを検索する
- Slackから情報を取得する
- 社内ドキュメントを検索する
それぞれに専用の実装が必要でした。
MCPは、この「AIがツールを使うための共通インターフェース」を提供します。
つまり、Claudeは「このツールにはこういう機能がある」という情報を理解し、必要に応じて自律的にツールを呼び出せるようになります。
ClickHouse MCPの場合、Claudeは次のような流れで動作します。
ユーザー
↓
自然言語
↓
Claude Desktop
↓
ClickHouse MCP Server
↓
ClickHouse Database
↓
結果取得・解釈
↓
自然言語で回答ここで重要なのは、ClaudeがSQLを書くだけではない点です。
必要であればテーブル一覧を確認し、スキーマを理解し、複数回の問い合わせを行いながら回答を組み立てることができます。
これは従来の「自然言語 → SQL変換ツール」とは大きく異なる点です。
実際に試してみる
今回の検証環境は以下の構成とします。
| 項目 | 内容 |
|---|---|
| LLM | Claude Desktop |
| MCP Server | ClickHouse MCP |
| Database | ローカルDocker上のClickHouse |
| データ | サンプルアクセスログ |
ログデータのスキーマは以下とします。
CREATE TABLE access_logs
(
timestamp DateTime,
service String,
endpoint String,
status_code UInt16,
response_time_ms UInt32
)
ENGINE = MergeTree()
ORDER BY timestamp;今回の技術検証では、このスキーマに合わせた access_logs テーブルをローカルDocker上のClickHouseに作成し、20行のサンプルアクセスログを投入します。
まず、初期データが正しく入っているかを確認します。
SELECT count() FROM access_logs;この結果が 20 になることを確認しました。
Claude Desktop から MCP 経由で接続すると、analytics データベースに access_logs と error_summary が存在することも確認できました。
このデータに対して、まず以下の質問を行います。
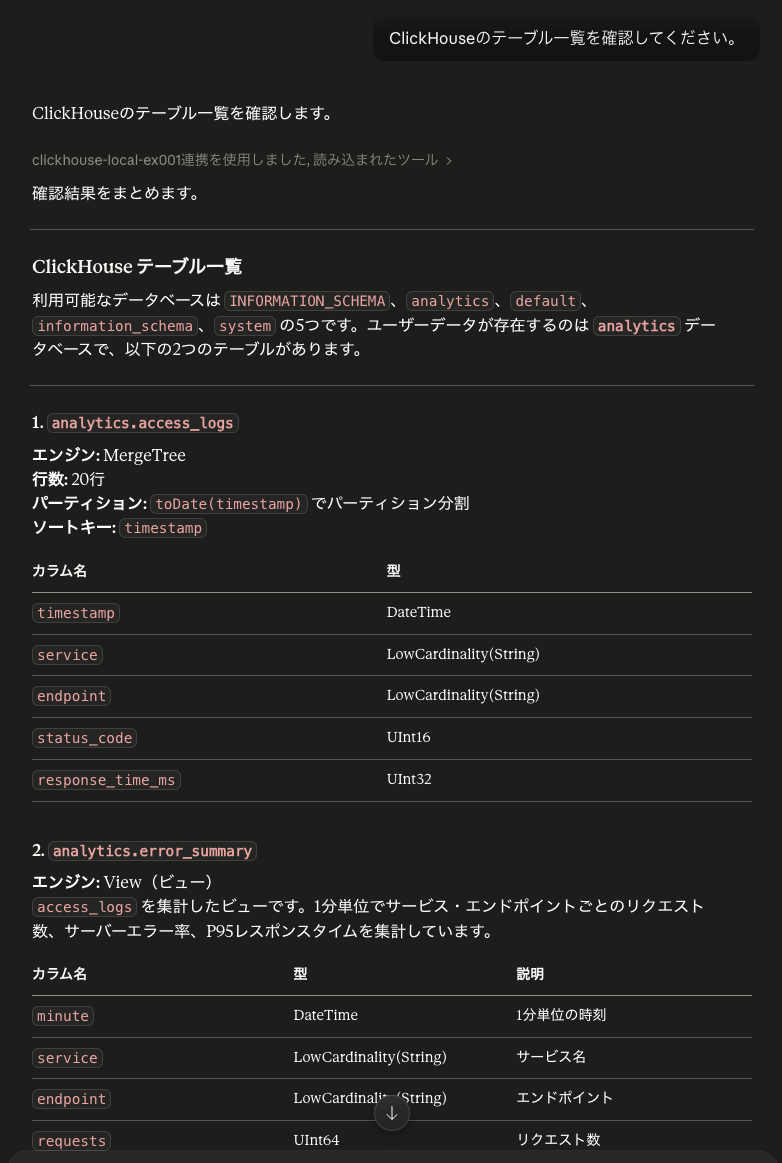
質問
「サンプルデータ内でエラーが多いAPIを教えて。実行したSQLも表示して」
Claudeは内部的に以下のような処理を行います。
- テーブル一覧を取得する
- access_logsのスキーマを確認する
- status_codeがエラー判定に利用できると推測する
- 集計SQLを生成する
- 結果を自然言語で要約する
最初に生成されたSQLは、次のようなものでした。
SELECT
endpoint,
service,
count() AS total_requests,
countIf(status_code >= 400) AS error_count,
round(countIf(status_code >= 400) / count() * 100, 2) AS error_rate_pct
FROM analytics.access_logs
GROUP BY endpoint, service
ORDER BY error_count DESC結果は、/api/search が6リクエスト中3件のエラーで最多でした。
ただし、ここで重要なのは、Claude が「エラー」を status_code >= 400 と解釈した点です。そのため、401 の /login や 404 の /docs/mcp もエラーとして集計されました。
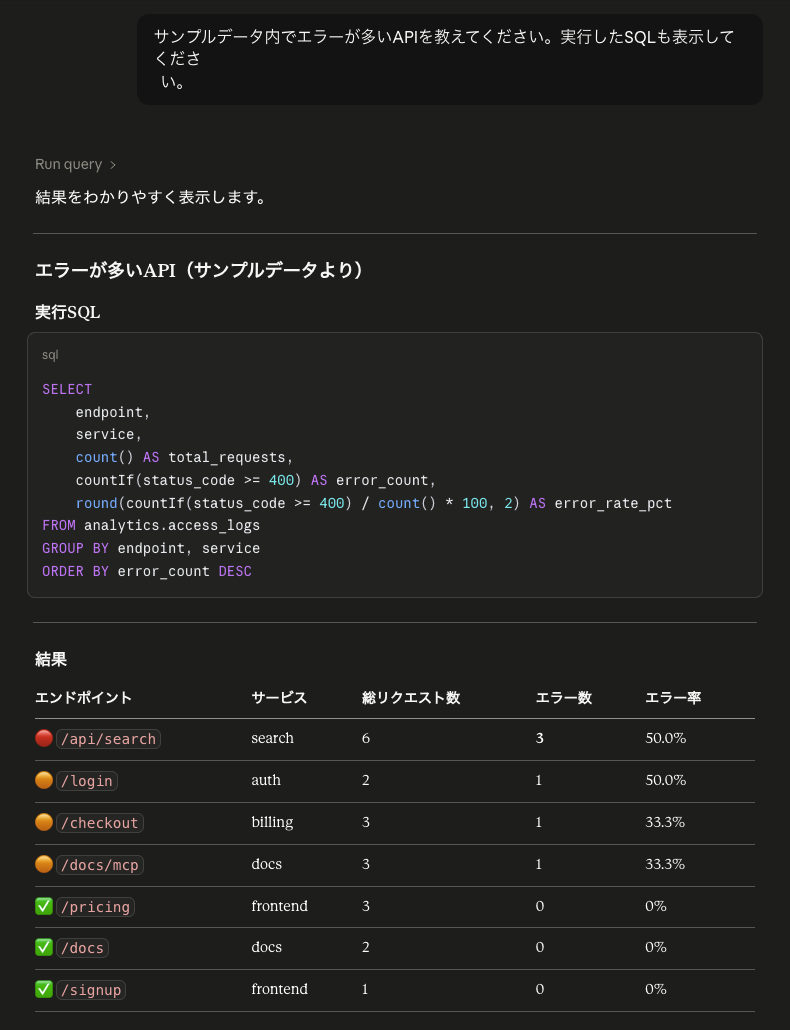
これは間違いというより、自然言語の曖昧さがSQL条件にそのまま出た例です。障害調査でサーバー起因のエラーだけを見たい場合は、「エラー」ではなく「500番台エラー」と明示する必要があります。
そこで、次に質問を変えました。
質問
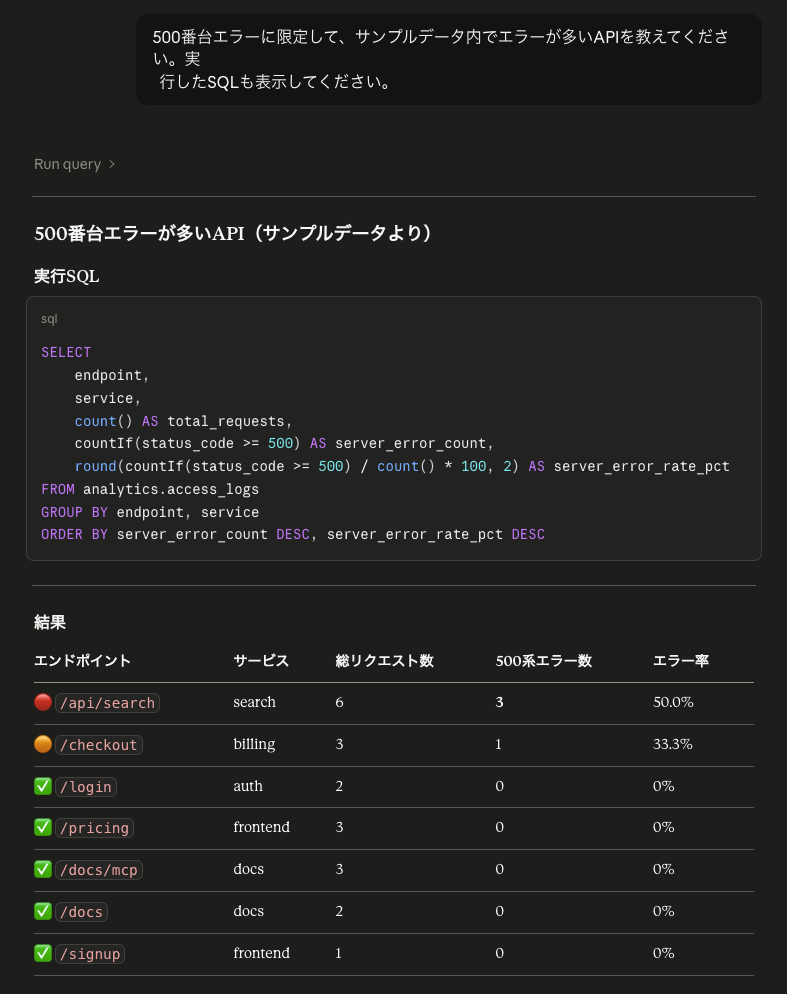
「500番台エラーに限定して、サンプルデータ内でエラーが多いAPIを教えて。実行したSQLも表示して」
この場合、生成されたSQLは期待に近いものになりました。
SELECT
endpoint,
service,
count() AS total_requests,
countIf(status_code >= 500) AS server_error_count,
round(countIf(status_code >= 500) / count() * 100, 2) AS server_error_rate_pct
FROM analytics.access_logs
GROUP BY endpoint, service
ORDER BY server_error_count DESC, server_error_rate_pct DESC結果は、/api/search が500番台エラー3件、/checkout が1件でした。これはサンプルデータの期待値どおりです。
この検証から、Claude Desktop + ClickHouse MCP で以下は確認できました。
- ClickHouse のテーブル一覧とスキーマを読み取れる
- 自然言語から ClickHouse SQL を生成できる
- SQLを実行し、結果を自然言語で要約できる
- 曖昧な言葉はClaude側で補完されるため、業務上の定義は明示する必要がある
つまり、自然言語でデータベースを操作する体験は成立します。ただし、正しい集計結果を得るには、SQLを書く代わりに「何をエラーとみなすか」「どの期間を見るか」「どの単位で集計するか」を自然言語で明確に伝える必要があります。
しかし、万能ではない
一方で、自然言語によるデータ操作には限界もあります。
例えば、
「いつもよりレスポンスが遅いAPIを教えて」
という質問は曖昧です。
今回の検証でも、「エラーが多いAPI」とだけ聞いた場合、Claude は 400番台と500番台をまとめてエラーとして扱いました。一方で、「500番台エラー」と条件を明示すると、期待どおりサーバーエラーだけに絞って集計できました。
「いつも」とは、
- 昨日と比較するのか
- 過去7日平均と比較するのか
- 同じ曜日・同じ時間帯と比較するのか
によってSQLが変わります。
人間であれば暗黙的に理解している文脈でも、AIにとっては複数の解釈が可能です。
この問題は、AIの性能向上だけでは完全には解決できません。
分析の目的やビジネス上の定義を、どこまでデータモデルやメタデータとしてAIに渡すかが重要になります。
本番利用で考えるべきこと
MCP経由で本番データベースをAIに接続する場合、最も注意すべきなのは権限設計です。
AIは悪意を持ちません。
しかし、与えられた権限の範囲で、利用者の意図に従って操作します。
そのため、
- 読み取り専用ユーザーを利用する
- アクセス可能なテーブルを限定する
- 個人情報を含むデータを分離する
- クエリ実行ログを監査する
といったデータガバナンス設計が必要になります。
「AIにデータベースアクセスを許可する」のではなく、「AIという新しい利用者を追加する」と考えるべきです。
まとめ
MCPによって、LLMは単なるチャットツールから、データベースを操作するインターフェースへ進化しました。
特にClickHouseのような高速な分析データベースとの組み合わせは相性が良く、ログ分析、障害調査、KPI確認といった探索的分析の体験を大きく変える可能性があります。
一方で、SQLそのものが不要になるわけではありません。
複雑な分析ロジック、曖昧なビジネス定義、権限設計など、人間が設計すべき領域は残ります。
今後のデータ分析では、「SQLを書ける人」と「書けない人」という区別よりも、「AIに適切な文脈を渡し、分析を導ける人」の価値が高まるかもしれません。
自然言語でデータベースを操作できるようになるほど、今度は人間側が「何を聞きたいのか」を正確に言語化する力が問われます。