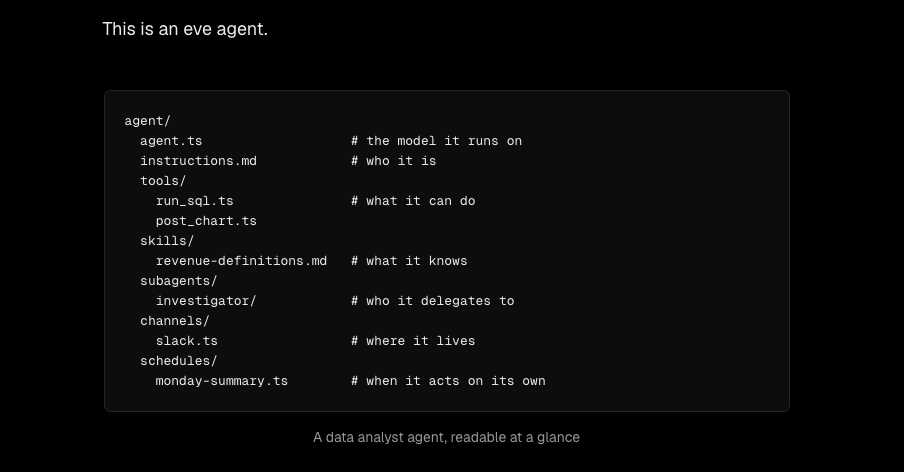
Flueを触る前に、まず何のフレームワークなのかを整理した
Flue 1.0 Betaを手元で触る前段として、Harness-first、Agent、Workflow、Skill、Tool、Sandbox、永続化まわりの考え方をざっくり整理したメモ。
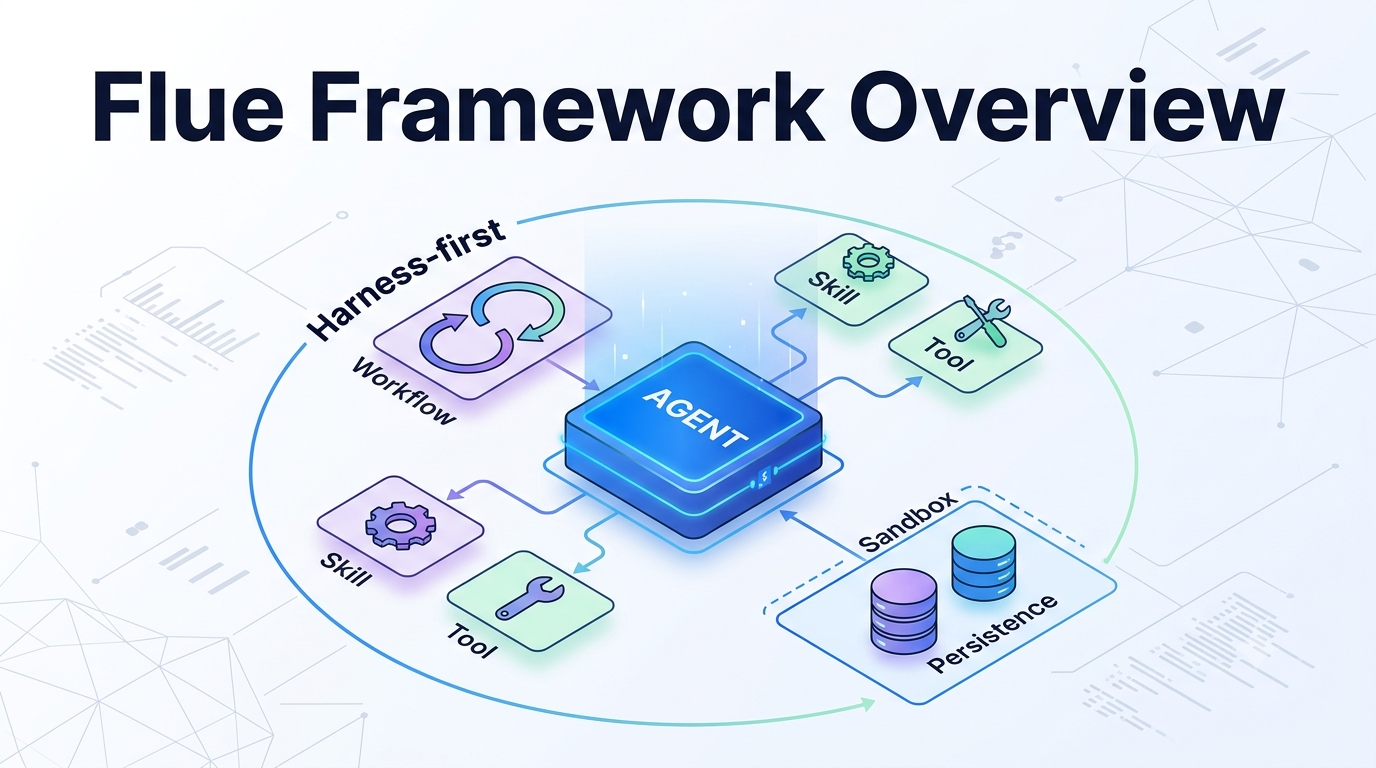
AIエージェントフレームワーク、Flue 1.0 Betaを触る前に、まず「これは何を作るためのフレームワークなのか」を整理しておきました。
最初にドキュメントを読んだ印象では、単にLLM APIを呼ぶための薄いSDKではなく、エージェントが実際の作業を続けられるようにするための実行環境、状態管理、ツール、スキル、サンドボックスをまとめて扱うための土台に見えます。
この記事はその下調べメモです。実際にQuickstartを動かした話は次の記事で書いています。
Flue 1.0 Betaをローカルで触ってみたら、Quickstartの一文でいきなり止まった https://llm-lab.dev/posts/flue-1-0-beta-local-check/
Quickstartで初期体験とCLIの実仕様を見て、次にAgent・Skill・Channel・Observabilityを組み合わせて実用寄りの小さいユースケースを作ってみたいと思ってました。 そのために、概要記事では以下の観点を先に整理しています。
- Quickstartの導線とCLIの実際の挙動は合っているか
src/agents/やsrc/workflows/の規約はどのくらい素直に使えるか- ToolとSkillはどう切り分けるべきか
- 外部入力を扱うAgentでSandboxをどう選ぶべきか
- Agentの継続ID、Workflowのrun ID、Observabilityは後から追える形になっているか
- Node.jsとCloudflareで永続化や運用の前提がどう変わるか
特に自分が見たかったのは、「AIエージェントらしい抽象」が実装時にどれくらい具体的な設計判断に落ちるかです。Skillはただの説明文なのか、実際に判定基準を安定させる単位になるのか。Sandboxは便利機能なのか、信頼境界として設計し直す必要があるのか。ChannelやObservabilityはサンプルの飾りなのか、運用するときに最初から入れておくべきものなのか。後続記事はその確認ログです。
Flueは何を中心に置いているのか
FlueはTypeScript製の、自律型AIエージェント向けフレームワークです。Node.jsやCloudflareなどの実行環境で動かせること、モデルやホスティング先に強く依存しないこと、長く続くセッションや中断からの回復を扱うことを狙っています。
ドキュメントを読んでいて一番目立つのは、Flueが「ハーネス」という言葉をかなり前面に出している点でした。ここでいうハーネスは、LLMが現実のタスクを進めるために必要な環境一式です。
- ファイルシステム
- ツール
- サンドボックス
- 指示やコンテキスト
- サブエージェント
- スキル
- MCPサーバーなどの外部接続
LLM単体はテキストを返すだけですが、これらを与えることで、ファイルを読み、必要な情報を集め、外部APIを呼び、長い作業を継続できるようになる。Flueはこの「モデルに何を持たせるか」を中心に設計しているようです。
Harness-firstという見方
従来のエージェント実装は、開発者が「あれを呼び、次にこれを呼び、失敗したらこうする」という手順をコードに落とし込む形になりがちです。これはワークフローとしては分かりやすいのですが、想定外の入力や曖昧な作業には弱くなります。
FlueのHarness-firstは、手順をすべて固定するよりも、モデルが作業に必要な道具と文脈を持てるようにする発想です。開発者は逐次的なスクリプトを書くのではなく、モデル、instructions、tools、skills、sandbox、subagentsを組み合わせて、タスクを解ける状態を作る。
この考え方は、Claude CodeやCodexのようなコーディングエージェントを使っているとかなり自然に感じます。人間が細かい手順を全部書かなくても、作業ディレクトリ、コマンド実行、検索、編集権限、プロジェクトルールが揃うと、エージェントはそれなりに動けます。Flueは、その構造をアプリケーション側で組み立てるためのフレームワークだと理解しました。
ただ、ここで気をつけたいのは、Harness-firstを「モデルに自由にやらせる」という話だけで理解しないことです。実際に作ると、どの情報をSkillに置くか、どの操作をToolにするか、どの入力を信頼しないか、どの処理をWorkflowに逃がすか、という細かい境界決めが出てきます。
後続のIssueトリアージAgentでいうと、Issue本文を読むだけの判定基準はSkillに置けます。一方、GitHubにコメントを書く、ラベルを付ける、過去Issueを検索する、といった副作用や外部参照はToolやChannel側の責務になります。この分離を曖昧にすると、「プロンプトに全部書いたけれど、どこからどこまでが安全な行動なのか分からない」状態になりそうでした。
Agentをどう作るのか
Flueでは、src/agents/配下にTypeScriptファイルを置き、createAgent()でエージェントを定義します。ファイル名がエージェント名になり、HTTPエンドポイントやdispatch対象として使われる規約です。
かなり単純化すると、形はこうです。
import { createAgent } from '@flue/runtime';
export default createAgent(() => ({
model: 'anthropic/claude-sonnet-4-6',
instructions: 'あなたはコードレビューを行うエージェントです。',
tools: [],
skills: [],
}));この中に、どのモデルを使うか、何を指示するか、どんなツールを持たせるか、どんなスキルを読ませるか、どのサンドボックスで動かすかを足していきます。
ローカル開発中はCLIから対話的に接続し、本番ではPOST /agents/<name>/<id>のようなHTTPエンドポイント、またはアプリケーション内のdispatch()から呼び出す形になるようです。idは継続的なセッションの識別子として使えるので、例えば「リポジトリ名 + issue番号」のような単位で同じエージェントインスタンスを継続させる設計ができます。
このidの設計は、実装時に思ったより重要そうです。単発のチャットなら適当なIDでも動きますが、GitHub Issueや問い合わせチケットのように、後から追加情報が来る対象では「何を同じセッションと見なすか」をアプリ側が決める必要があります。
後続記事ではrepository.full_name#issue.numberのようなIDを使いました。これは、同じIssueへの追加イベントを同じ継続インスタンスに寄せたいからです。Flueがセッションを持てるとしても、どの粒度で状態を継続するかはフレームワークではなくアプリケーションの設計になります。
ToolとSkillは別物
Flueを読むときに最初に混ざりやすいのが、ToolとSkillです。名前だけ見るとどちらも「エージェントに能力を足すもの」に見えますが、役割は違います。
Toolは、実行可能なコードです。注文状況をDBから検索する、GitHubにコメントを書く、外部APIへ問い合わせる、といった実際の行動を担います。モデルがツールを呼ぶと、アプリケーション側の関数が実行され、結果がモデルに返ります。
一方でSkillは、再利用可能な指示書です。コードレビュープロセス、障害調査の観点、チケット分類ルール、社内の文章トーンなど、専門的な作業のやり方をMarkdownとしてまとめます。Skill自体は実行能力を増やしません。あくまでモデルの判断や作業手順をガイドするものです。
自分の理解では、Toolは「できること」、Skillは「どうやるか」です。エージェントに外部システムを操作させたいならToolが必要で、判断基準や作業観点を安定させたいならSkillが効きます。
この切り分けは、Issueトリアージのような小さいAgentでもすぐ出てきます。severityの定義、再現情報が足りているかの判定、ラベル候補の考え方はSkillにできます。しかし、実際にGitHubへコメントを書き込む、ラベルを付与する、リポジトリの設定を読む、といった部分はToolやChannelとして明示したほうが責務がはっきりします。
ここを曖昧にして「全部instructionsで頑張る」に寄せると、最初は速く作れますが、あとから挙動を観測したり、権限を絞ったり、テストしたりするときに詰まりそうです。Flueの面白いところは、この分離を最初からフレームワークの語彙として持っている点でした。
Skillの組み込み方
SkillはSKILL.mdとして書き、frontmatterにnameとdescriptionを持たせる形式です。プロジェクト内に置いてTypeScriptから明示的にimportする方法と、サンドボックス内の.agents/skills/から自動検出させる方法があります。
---
name: code-review
description: Reviews code changes using the project review checklist.
---
# Code Review
Check correctness, security, maintainability, and missing tests.
Do not comment on unrelated style issues unless they affect behavior.TypeScript側では、MarkdownをSkillとしてimportしてAgentに渡します。
import reviewSkill from '../skills/code-review/SKILL.md' with { type: 'skill' };
export default createAgent(() => ({
model: 'anthropic/claude-sonnet-4-6',
skills: [reviewSkill],
}));この作りは、CodexのSkillやClaude Codeのカスタム指示に近い感覚があります。アプリケーションコードに全部の振る舞いを書き込むのではなく、作業の型をMarkdownとして分離できるのは、運用しながら調整するには扱いやすそうです。
Sandboxは信頼境界として見る
Flueには複数のサンドボックスがあります。ざっくり分けると、デフォルトの仮想サンドボックス、Node.js環境で使えるローカルサンドボックス、Daytonaなどを使うリモートサンドボックスです。
仮想サンドボックスは軽量なインメモリ環境で、ホストのファイルシステムへ直接アクセスしません。ローカルサンドボックスはホストのファイルシステムやシェルに触れます。リモートサンドボックスは隔離されたLinux環境を使う選択肢です。
ここは「どれが便利か」だけで選ぶと危ない部分です。特にlocal()は、信頼できるローカル開発や使い捨てのCIランナーなら便利ですが、外部ユーザーから届く入力を処理する常駐サービスで使うものではありません。サンドボックスは作業環境であると同時に、信頼境界そのものです。
実際に後続記事でGitHub IssueトリアージAgentを作ったときも、最初はローカルサンドボックスを使いかけましたが、Issue本文は外部入力なので、最終的には仮想サンドボックスへ寄せる判断になりました。
この判断は、今回のシリーズで一番「概要を読んでおいてよかった」と感じた部分です。ドキュメントを雑に読むと、local()はファイルもシェルも使えて便利そうに見えます。ただ、外部から届くIssue本文を処理するAgentにホストアクセスを渡すのは、便利さより信頼境界の問題になります。
つまり、Sandbox選びは機能選定ではなく運用設計です。ローカルで自分だけが試す検証、使い捨てCIランナー、本番の常駐サービス、マルチテナント環境では、それぞれ前提が違います。Flueを触るときは、最初に「この入力は誰から来るのか」「このAgentは何に触れてよいのか」を決めてからSandboxを選ぶほうがよさそうです。
Subagentはコンテキスト分離の道具
Flueにはサブエージェントへタスクを委譲する考え方もあります。親エージェントがすべての調査、分類、レビュー、修正案作成を抱えるのではなく、専門の子エージェントに任せる形です。
サブエージェントの利点は、単に並列化できることだけではありません。親のコンテキストを汚さずに探索的な作業をさせられること、子エージェント側に必要なツールだけを持たせられること、結果だけを親が統合できることが大きいです。
人間の仕事でも、調査担当、実装担当、レビュー担当が分かれているほうが進めやすい場面があります。Agent設計でも同じで、ひとつの巨大なプロンプトに全部詰めるより、役割ごとに分けたほうが見通しがよくなる場面は多そうです。
AgentとWorkflowの耐久性は違う
FlueにはAgentだけでなくWorkflowもあります。ここで気をつけたいのは、耐久性や回復の考え方が同じではない点です。
Agentは継続的なセッションとして扱われ、中断後の再開が重要な設計対象になります。途中までの出力、ツール呼び出し、会話履歴を踏まえて、安全に続きを進める方向です。
一方でWorkflowは、有限の関数実行に近いものです。再試行は「途中から再開」ではなく、新しい実行として扱う設計になります。そのため、外部システムに影響する処理をWorkflowに入れる場合は、アプリケーション側で冪等性を設計する必要があります。
例えば、チケット作成、コメント投稿、支払いリクエスト、メール送信などは、失敗時に同じ処理が二重実行されると困ります。Webhook由来の処理なら配信IDやイベントIDを保存して重複排除する、外部APIには冪等性キーを渡す、といった設計が必要です。
このあたりはLLM以前の普通の分散システム設計に近い話ですが、AgentやWorkflowが絡むと「モデルが賢くやってくれる」という気分になりやすいので、むしろ明示的に気をつけたいところです。
QuickstartではWorkflowのrun IDが見え、IssueトリアージAgentではAgentのidやsubmissionIdが見えました。ここは地味ですが、後から運用ログを追うときにかなり重要です。モデルの出力だけを見るのではなく、「どの入力が、どのセッションやrunに入り、どの操作で失敗したか」を追えることが、AgentOps的には本体に近いです。
Flueを触る前は、AgentとWorkflowの違いを「LLMに任せるもの」と「決まった処理」くらいに見ていました。ただ、実際にログやエラーを見ると、再開できる単位、再試行の単位、二重実行を避ける責務が違います。ここを理解しておかないと、動くデモから運用するAgentへ進むところで詰まりそうです。
永続化はデプロイ先で変わる
Flueの会話履歴やWorkflow実行記録は、PersistenceAdapterで永続化できます。ただし、設定方法は実行環境によって違います。
Cloudflareにデプロイする場合は、Durable ObjectsとSQLiteを使う構成が前提になり、Flue側で必要な状態保存が組み込まれるようです。一方、Node.js環境ではデフォルトがインメモリSQLiteなので、プロセス再起動で状態は消えます。永続化したい場合はsrc/db.tsなどにSQLiteやPostgreSQLのAdapterを定義する必要があります。
ただし、ここで保存されるのはFlueランタイムの状態です。顧客データ、業務データ、アプリケーション固有の永続データまで勝手に面倒を見てくれるわけではありません。Agentの会話履歴とビジネスデータは、分けて考えたほうがよさそうです。
触る前の時点で気になったところ
ドキュメントを読んだ段階では、Flueは「LLM APIを叩く便利ライブラリ」ではなく、Agentアプリケーションをちゃんと長生きさせるための実行基盤に寄せている印象でした。
特に気になったのはこのあたりです。
- Agentを継続セッションとして扱う
- ToolとSkillを分ける
- サンドボックスを信頼境界として扱う
- Workflowには冪等性設計が必要
- Node.jsとCloudflareで永続化の考え方が違う
逆に言うと、軽いチャットBotを作るだけなら少し大きく感じるかもしれません。Issueトリアージ、コードレビュー、調査、複数ステップの業務補助のように、状態や外部連携や観測が必要になる用途で効いてきそうです。
続きは実装検証ログとして分けて記事にしていこうと思います!