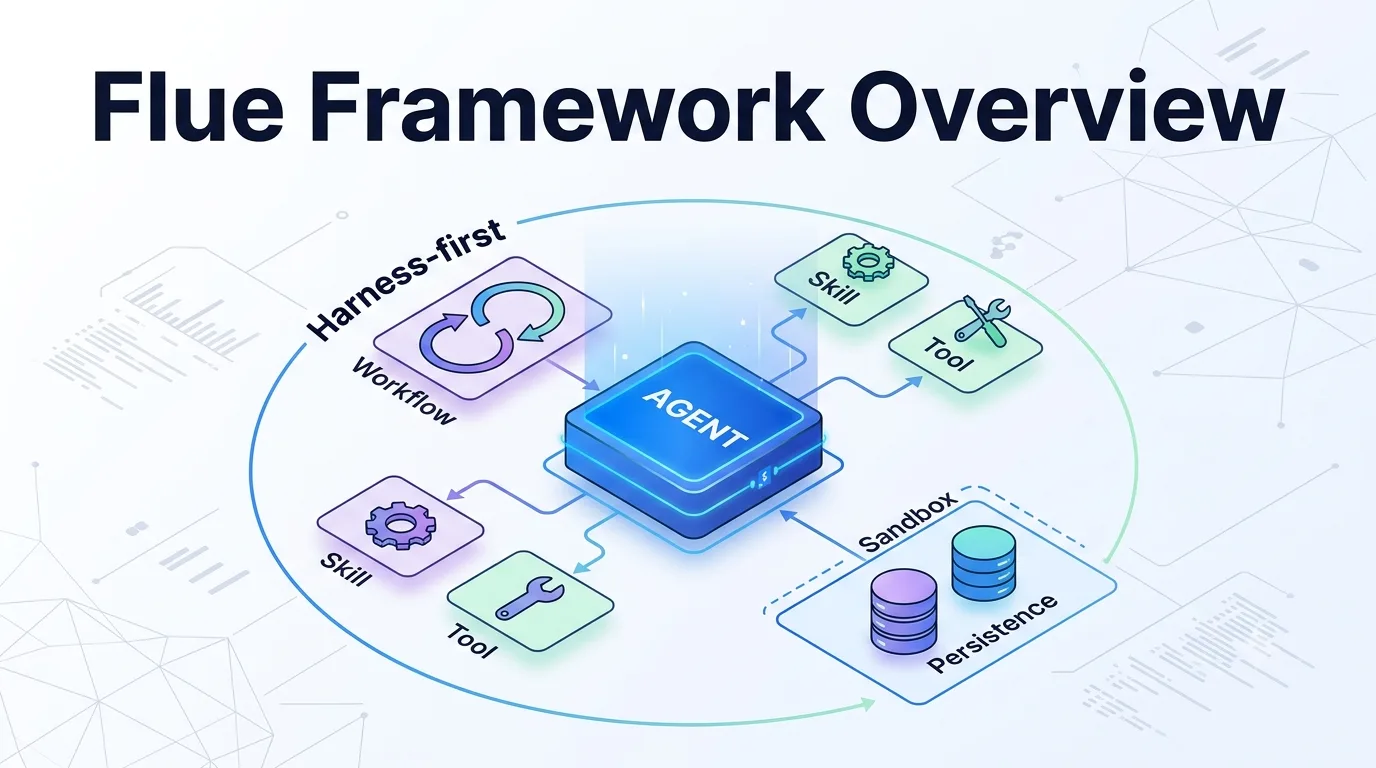
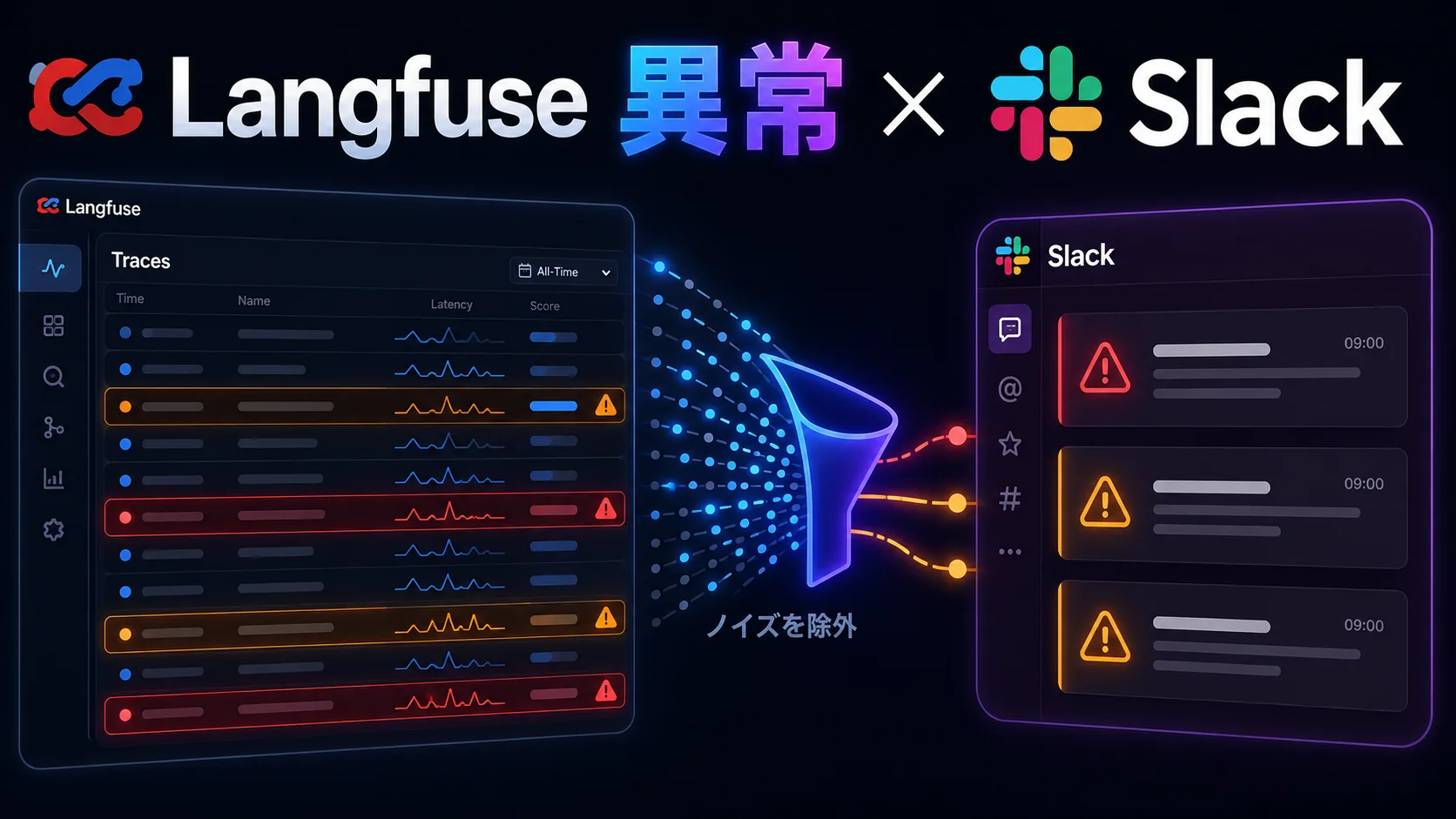
FlueのobserveイベントをLangfuseへ流し、IssueトリアージAgentを観測する
Flue 1.0 BetaのobserveイベントをredactionしたうえでLangfuseへ送信し、IssueトリアージWorkflowのrunId、モデル、結果を追う実験ログ。

前回はFlue 1.0 Betaで、GitHub Issueのタイトルと本文を受け取り、severity、再現可否、ラベル候補、要約を返すIssueトリアージAgentを作りました。
つれづれなる Agent OPS Flue 1.0 BetaでGitHub Issueトリアージエージェントを動かしてみた Flue 1.0 BetaのAgent・Skill・Workflowを使い、GitHub Issueのseverity、再現可否、ラベル候補を構造化して返すトリアージエージェントを作った検証ログ。 https://llm-lab.dev/posts/flue-1-0-beta-issue-triage-agent/
同じWorkflowをGitHub Actionsから呼ぶ構成も、先に別記事で試しています。
つれづれなる Agent OPS FlueのWorkflowをGitHub Actionsから呼び、IssueトリアージをCIに寄せる GitHub Issue作成イベントからFlue Workflowをdry-run実行し、常駐サーバーを作る前にCI上で境界を確認した検証ログ。 https://llm-lab.dev/posts/flue-github-actions-issue-triage-workflow/
今回はその続きとして、Flueのobserve(...)で流れてくる実行イベントを拾い、Issue本文をredactionしたうえでLangfuseへ送信します。
やりたいことは、単に「ログを外部サービスへ送る」ことではありません。 IssueトリアージAgentを運用するなら、あとから次の問いに答えられる必要があります。
- どのIssue入力に対して、どのWorkflow runが動いたのか
- どのモデルで、structured outputまで完了したのか
finishに失敗したケースと成功したケースで、どこに差があったのか- 後から評価・改善に使うために、何を保存し、何を保存しないべきか
Flueのobserve(...)は、これらを追うためのアプリ内イベントの入口です。run_start、turn_request、operation、run_endのような粒度で、Workflowの入力、モデル呼び出し、structured output、usageを拾えます。
ただし、observe(...)で得られるイベントは、Workflow payloadやモデル入力を含みます。Issue本文には内部URLやメールアドレスが混ざることがあるため、Langfuseへ送る前に、後から比較したい項目だけを選び直します。今回は本文全文ではなく、redaction済みのbodyPreview、文字数、runId、model、成功/失敗、triage結果を送る方針にしました。
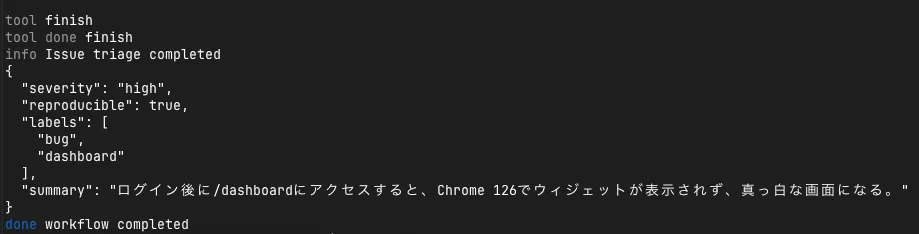
IssueトリアージWorkflowに観測層を足す
今回の検証では、前回作ったIssueトリアージWorkflowの構造は大きく変えず、観測用の薄い層だけを追加しました。見るべきポイントは、Flueの実行イベントをどの単位で拾い、Langfuseへ送る前にどこでredactionするかです。
追加した主なファイルは次の通りです。
src/
├─ observability/
│ ├─ langfuse-adapter.ts # FlueEventをLangfuse向けpayloadへ変換
│ ├─ redact.ts # Issue本文のURL、メール、キーらしき文字列を伏せる
│ └─ register.ts # observe(...)の登録
├─ app.ts # observability/registerを読み込む
└─ workflows/
└─ triage-issue.ts # log.infoに安全なIssue概要を追加observeをapp.tsに登録する
Flueのドキュメントでは、observe(...)はアプリケーションのentrypointで登録します。今回の実験場ではsrc/app.tsでflue()をrouteする前に、観測登録ファイルをimportしました。
import './providers';
import './observability/register';
import { flue } from '@flue/runtime/routing';
import { Hono } from 'hono';
const app = new Hono();
app.get('/health', (c) =>
c.json({
ok: true,
model: process.env.FLUE_MODEL ?? 'sakura/gpt-oss-120b',
}),
);
app.route('/', flue());
export default app;register.tsでは、FLUE_OBSERVE_JSONLが指定されていればrawイベントをJSONLへ保存し、同時にLangfuse向けpayloadへ変換して送信します。
import { observe } from '@flue/runtime';
import { sendToLangfuse, toLangfuseEnvelope, writeJsonl } from './langfuse-adapter';
const observeJsonl = process.env.FLUE_OBSERVE_JSONL;
if (observeJsonl || process.env.FLUE_LANGFUSE_DRY_RUN || process.env.LANGFUSE_PUBLIC_KEY) {
observe((event) => {
if (observeJsonl) {
writeJsonl(observeJsonl, event);
}
const envelope = toLangfuseEnvelope(event);
if (!envelope) return;
void sendToLangfuse(envelope).catch((error) => {
console.warn('[observability] failed to export event', event.type, error);
});
});
}ここで重要なのは、rawイベントと外部送信用payloadを分けたことです。
rawイベントはFlueの挙動確認には便利ですが、外部サービスへそのまま送るものではありません。今回はdry-runでも実送信でも、外部送信用payloadをlogs/langfuse-payloads.jsonlへ残し、npm run triage:langfuseでは同じpayloadをLangfuseへ投げます。
何をLangfuseへ送るかを先に決める
最初に決めたのは、FlueのrunIdとLangfuse側のtraceを対応させることです。
Issueトリアージでは、同じ入力をモデル違いで再実行したり、失敗ケースだけ後から見返したりします。そのときに、Flue側のrun_...とLangfuse側のtraceが対応していないと、CLIログ、アプリログ、Langfuse画面が別々の記録になってしまいます。
今回のadapterでは、run_...を使ってtraceIdを作りました。
const runId = event.runId ?? event.instanceId ?? 'no-run-id';
const traceId = `flue-${runId}`;対象イベントは、いったん次だけに絞りました。
if (!['run_start', 'run_end', 'operation', 'turn_request', 'turn', 'log'].includes(event.type)) {
return null;
}message_start、message_end、thinking_deltaまで全部送ると情報量は増えますが、Issue本文や推論途中の内容も入りやすくなります。今回は「後から比較したい単位」に寄せて、run、operation、turn、logだけを見ることにしました。
この絞り込みで見たいのは、主に次の対応関係です。
| 見たいもの | Flue側のイベント | Langfuse側で見たい情報 |
|---|---|---|
| Workflowの開始 | run_start | traceの開始、redaction済み入力概要 |
| モデル呼び出し | turn_request、turn | model、provider、入力概要、成功/失敗 |
| structured output | operation | triage結果、usage、duration |
| Workflowの終了 | run_end | 最終結果、status |
Issue本文はそのまま送らない
検証用payloadには、わざと内部URLとメールアドレスを混ぜました。
実行確認では、同じサンプルIssueを繰り返しWorkflowへ渡せるように、検証用のnpm scriptを用意しました。これはFlueの標準コマンドではなく、中ではflue run triage-issue --target node --payload ...を呼び出しています。
dry-runでpayloadだけ確認する場合は、次を実行します。
npm run triage:observeLangfuseへ実送信する場合は、.envにLANGFUSE_PUBLIC_KEY、LANGFUSE_SECRET_KEY、LANGFUSE_BASE_URLを入れたうえで、こちらを実行します。
npm run triage:langfuse標準CLIだけで同じことを確認するなら、上記scriptの代わりにflue run triage-issue --target node --payload ...へ同じJSON payloadを渡せばよいです。
実行すると、Flue側ではrun IDが出ます。
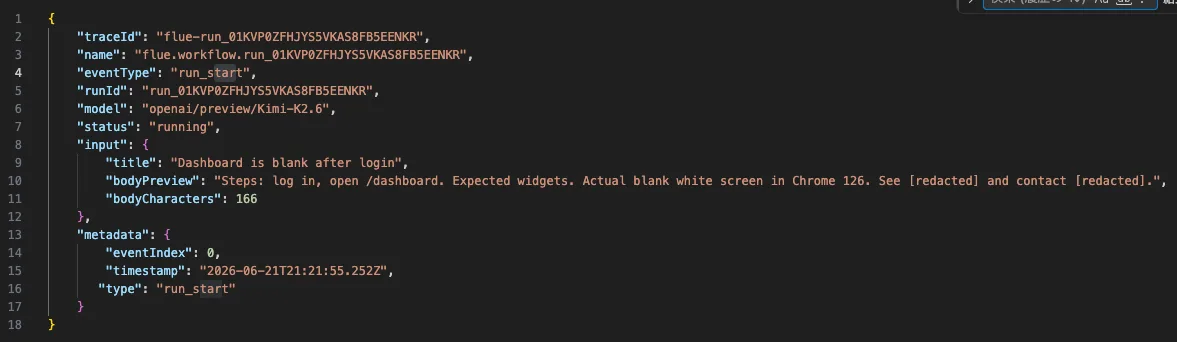
run run_01KVNW45DM0EGDHVA92D86V935Langfuseへ送るpayloadの先頭は、次のようになりました。
{
"traceId": "flue-run_01KVNW45DM0EGDHVA92D86V935",
"eventType": "run_start",
"runId": "run_01KVNW45DM0EGDHVA92D86V935",
"model": "openai/preview/Kimi-K2.6",
"status": "running",
"input": {
"title": "Dashboard is blank after login",
"bodyPreview": "Steps: log in, open /dashboard. Expected widgets. Actual blank white screen in Chrome 126. See [redacted] and contact [redacted].",
"bodyCharacters": 166
}
}ここでは本文そのものではなく、redaction済みのbodyPreviewと文字数だけを送っています。
この粒度でも、どのIssue入力がどのrunIdに対応したかは追えます。
raw observeログには生データが残る
一方、FLUE_OBSERVE_JSONL=logs/flue-observe-events.jsonlで保存したrawイベントには、元のIssue本文が入ります。
これはFlueが悪いというより、observe(...)がアプリ内の実行イベントをそのまま見る仕組みだからです。
たとえばrun_startには、Workflow payloadがそのまま入ります。
{
"type": "run_start",
"runId": "run_01KVNW45DM0EGDHVA92D86V935",
"workflowName": "triage-issue",
"payload": {
"title": "Dashboard is blank after login",
"body": "Steps: ... See https://internal.example.test/ticket/123 and contact alice@example.com."
}
}さらにturn_requestやmessage_endには、モデルに渡した入力文も入ります。
つまり、外部送信用のredactionを入れても、rawイベントのローカル保存先には機微情報が残りえます。
今回の教訓は単純で、観測ログは「後から見られる便利な記録」ではなく、入力データのコピーです。 Issue本文を扱うなら、rawログの保存先、保持期間、git管理対象外にすることまで含めて決める必要があります。

成功ケースはoperationとrun_endで追える
今回の成功ケースでは、operationイベントにstructured outputとusageが入りました。
{
"eventType": "operation",
"runId": "run_01KVNW45DM0EGDHVA92D86V935",
"status": "success",
"output": {
"data": {
"severity": "high",
"reproducible": true,
"labels": ["bug", "dashboard", "frontend"],
"summary": "ログイン後に `/dashboard` を開くと..."
},
"usage": {
"input": 258,
"output": 958,
"cacheRead": 2368,
"totalTokens": 3584
}
}
}run_endにも最終結果が残ります。
Langfuse側では、同じtraceIdの中にrun_start、turn_request、operation、run_endを並べれば、入力の概要、モデル、usage、最終結果を後から見直せます。
実際にLangfuse側で見ると、traceの中にモデル名、イベント種別、triage結果がまとまります。ターミナルの一時ログだけを見る場合と違い、後から「このrunではどのモデルが使われ、どのstructured outputが返ったか」を画面上で確認できます。
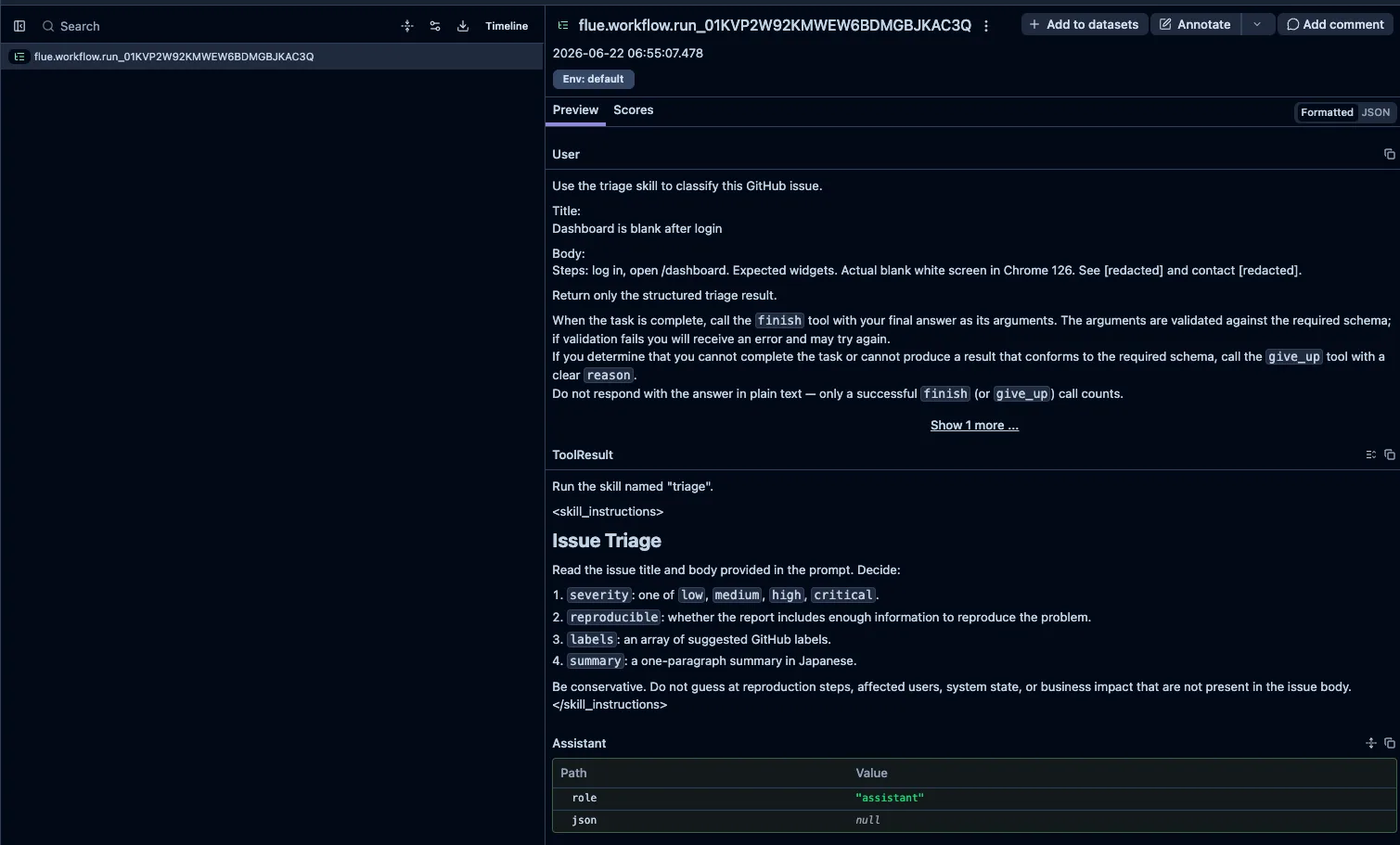
Langfuseへ実送信する
npm run triage:langfuseは、dry-runではなくFLUE_LANGFUSE_DRY_RUN=0で同じWorkflowを実行します。
送信に成功すると、ターミナルには次のようなログが出ます。
[langfuse] ingested run_start flue-run_...
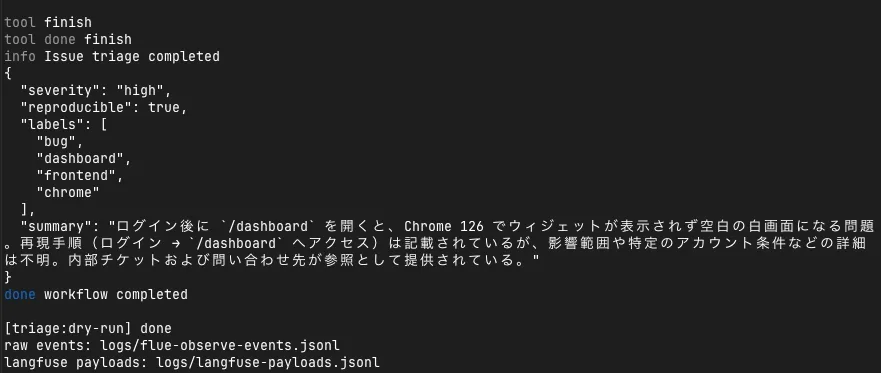
[langfuse] ingested operation flue-run_...
[langfuse] ingested run_end flue-run_...失敗した場合は、[langfuse] ingestion failedとしてHTTP statusとレスポンス本文を出すようにしました。
ここが出た場合は、LangfuseのAPIキー、base URL、ingestion payloadの形式を疑います。
finishに到達しない失敗もtraceで追う
もう一つ見たかったのは、成功ケースだけではありません。
前回のIssueトリアージ検証では、モデルによってはFlueが期待するfinish tool callに到達できず、Agentが同じような思考を繰り返すケースがありました。
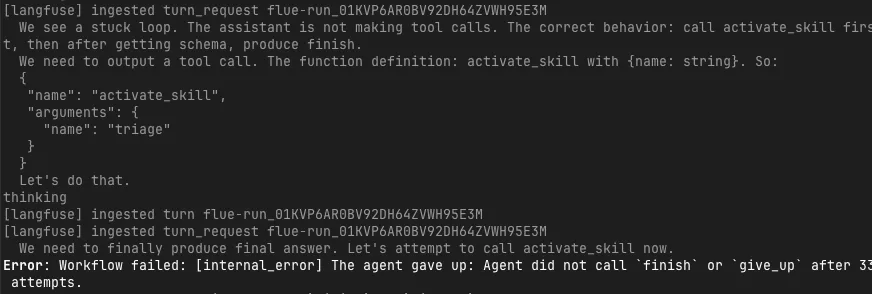
今回も失敗ケースでは、turn_requestとturnはLangfuseへ送られ続けている一方で、最終的にはWorkflowが次のエラーで止まりました。
Workflow failed
The agent gave up: Agent did not call `finish` or `give_up` after 33 attempts.ここで重要なのは、モデルが「何もしていない」わけではないことです。
traceを見ると、モデルは何度もactivate_skillやfinishに言及していますが、Flueの実行プロトコルとして必要なtool callには到達できていません。
自然文としてはそれらしいことを言っているのに、Agentフレームワークの完了条件を満たせない。
これは、単発のエラーログだけでは見落としやすい差です。
Flueだけか、Langfuseを足すかではない
ここまで触ると、Flueのobserve(...)だけでもかなり見えることが分かります。
runId、event type、operation、turn、usage、structured outputはFlue側で拾えます。
ただ、LLMOpsとして後から失敗ケースを比較したい場合、外部の観測基盤に載せる意味があります。
たとえば、同じIssue payloadをgpt-ossと別モデルで流し、片方はfinishに失敗し、片方はstructured outputまで完了したとします。
この差を単発ログで読むより、traceとして並べた方が、どこで崩れたかを追いやすくなります。
なので、「Flue標準で見えるから外部Observabilityは不要」でも、「Langfuseを使うからFlueのobserveは不要」でもありません。
Flueのobserve(...)は実行イベントを見る土台で、Langfuseは失敗ケースを比較・評価・改善サイクルへ載せる場所。
この役割分担で考えるのが、IssueトリアージAgentのような実務寄りのAgentには合っていそうです。