EveのTUIとHTTPイベント列でtool callingの見え方を比べる
VercelのエージェントフレームワークEveで同じ天気ツール呼び出しをTUIとHTTP APIから観測し、開発者向け表示と外部連携向けイベント列の違いを整理した検証ログ。

TUIで見えるものをそのまま外部連携してもいいのか?
前回の記事では、Eveのtool callingをLangfuseへ流す入口を確認しました。TUIでget_weatherツールが呼ばれ、Hookやinstrumentationから観測できることも分かりました。

TUIはかなり見やすいのですが、外部のUIや観測基盤へつなぐ場合に必要なのは、人間向けに整形された表示ではなく、イベント列です。TUIで「ツールが呼ばれた」と分かることと、HTTP streamで「どのイベントを拾えば同じ事実を復元できるか」が分かることは、別の確認項目です。
今回は、同じ天気ツール呼び出しをTUIとHTTP APIの両方から見て、Eveの実行がどの粒度で表現されるのかを整理しました。検証したEveは0.11.x系で、対象はローカルのダミー天気ツールです。
検証に使った最小ツール
ツール自体は前回までと同じく、都市名を受け取り、固定の天気データを返すだけの小さなものです。
// agent/tools/get_weather.ts
import { defineTool } from "eve/tools";
import { z } from "zod";
export default defineTool({
description: "Get the current weather for a city. Returns dummy data for local testing.",
inputSchema: z.object({
city: z.string().describe("City name, e.g. Tokyo"),
}),
async execute({ city }) {
return {
city,
temperatureC: 26,
condition: "partly cloudy",
note: "this is dummy data from a local check, not a real weather API",
};
},
});ここで重要なのは、天気情報そのものではありません。モデルがget_weatherを呼び出し、その入力と出力がEveのイベント列にどう現れるかです。
TUIは開発中の理解に強い
まずTUIから同じ質問を投げると、Eveはツール呼び出しを人間が読める形に整えて表示します。get_weatherが呼ばれたこと、入力がcity="Tokyo"だったこと、返ってきた温度や天気条件が会話の中で使われたことが、1画面で把握できます。
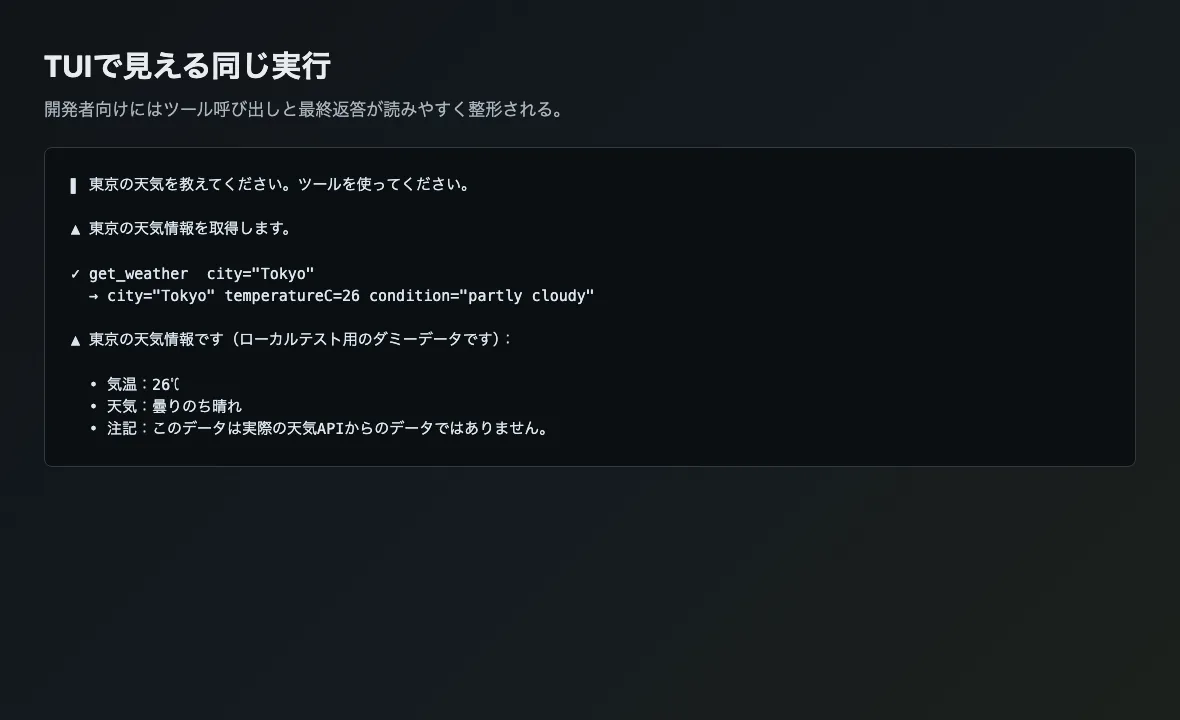
開発中に「いまツールが呼ばれたか」「モデルがツール結果を読んだか」を見るなら、TUIは十分に便利です。ログを細かく読まなくても、実行の流れを追えます。
一方で、TUIの表示はあくまで開発者向けに加工されたビューです。独自UIやLangfuseのような観測基盤に流す場合は、どのイベントを根拠にツール呼び出しを再構成するかを別に決める必要があります。
HTTP APIではイベント列として見える
次に、Eve Clientで同じ1ターンを送って、返ってきたイベント列を確認しました。ここで使ったスクリプトはEve公式CLIではなく、検証用に用意した小さなものです。起動中のEveサーバーへ1ターン送信し、レスポンスに含まれるイベントのうち、tool callingの確認に必要な部分だけを抜き出しています。
import { Client } from "eve/client";
const client = new Client({ host: "http://127.0.0.1:3000" });
const session = client.session();
const response = await session.send("東京の天気を教えてください。ツールを使ってください。");
const result = await response.result();
console.log(result.events.map((event) => event.type));実行すると、ツール呼び出しはactions.requestedとaction.resultの組として現れました。前者にはモデルが要求したアクション、後者には実行結果が入ります。最終返答は別のmessage.completedとして流れるため、ツール出力とユーザー向け回答を分けて扱えます。
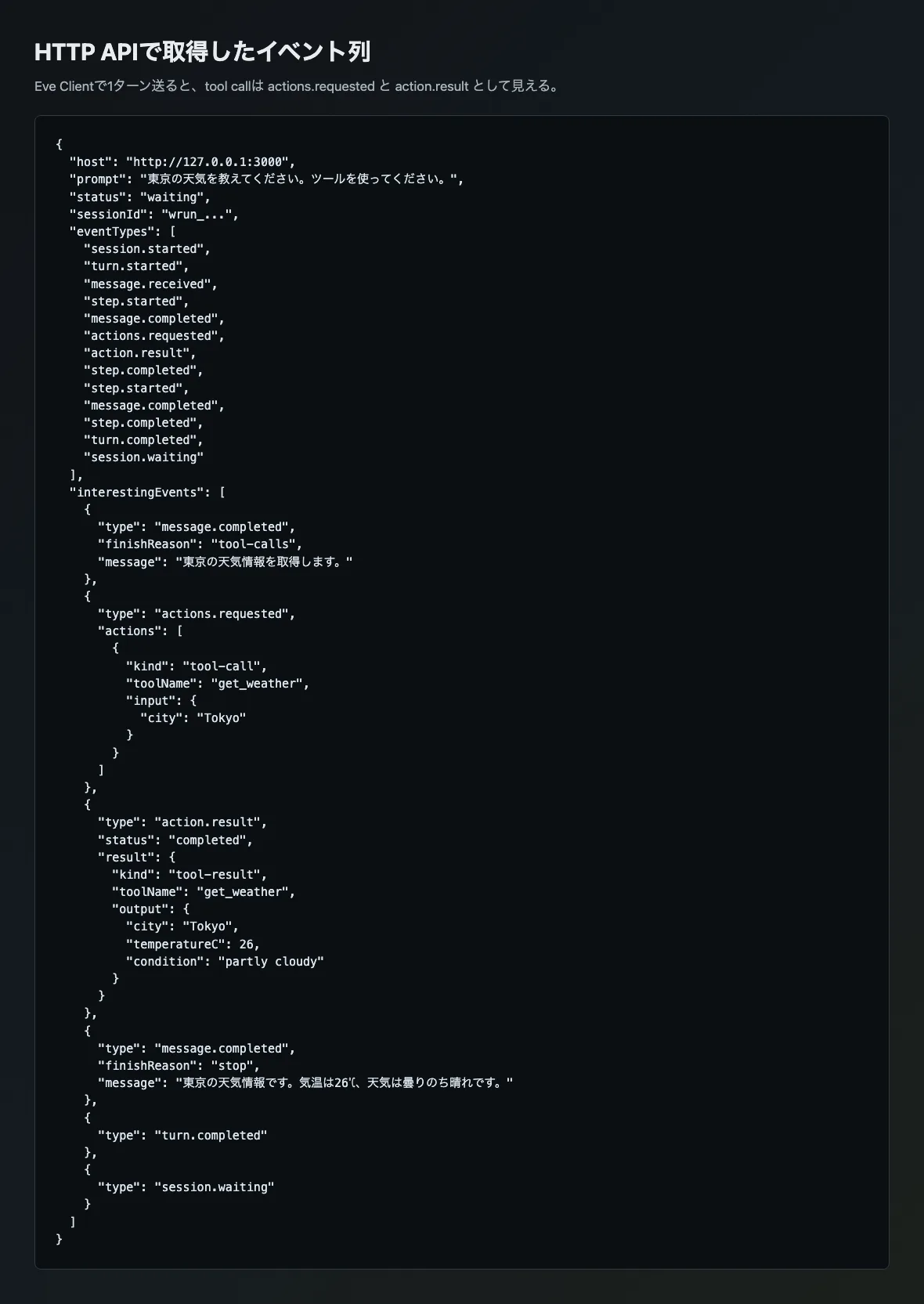
今回の検証では、イベント列の中心は次の流れでした。
| イベント | 観測できること |
|---|---|
message.completed with finishReason: "tool-calls" | モデルがツール呼び出しに進む前の短い発話 |
actions.requested | 呼び出したツール名、入力、call単位の情報 |
action.result | ツール実行の成否、出力、ツール名 |
message.completed with finishReason: "stop" | ツール結果を読んだ後の最終返答 |
session.waiting | セッションが次の入力待ちになったこと |
ここでようやく、TUIで見えていた「ツールを呼んで答えた」という事実を、外部連携で使える構造に分解できます。観測や独自UIでは、最終返答だけを保存しても足りません。少なくともactions.requestedとaction.resultを拾わないと、どのツールが、どの入力で、どの結果を返したかが後から分からなくなります。
TUIとHTTPイベント列の使い分け
今回の範囲で見る限り、TUIとHTTPイベント列は優劣ではなく用途が違います。TUIは開発中の認知負荷を下げるビューで、HTTPイベント列は外部システムが扱うための素材です。
特にLLMOpsの観点では、次の分担が自然だと感じました。
| 用途 | 向いている入口 |
|---|---|
| 開発中にツール呼び出しを目視確認する | TUI |
| 独自UIで進行状況を表示する | HTTP stream |
| Langfuseなどへツール入出力を送る | HookまたはHTTPイベント列 |
| evalでツール呼び出しを検証する | Eve evalのassertion |
TUIで見えたから大丈夫、ではなかった。
TUIで分かることは重要ですが、その表示をそのまま運用時の記録形式にできるわけではありません。逆に、HTTPイベント列だけを見ると粒度は十分でも、人間がデバッグするには少し読みづらい。両方を見て初めて、開発体験と運用時の観測設計の境界が見えてきます。
今回の検証で残った判断
今回確認できたのは、Eve Clientで1ターンを送った場合に、tool callingがactions.requestedとaction.resultとして観測できることです。TUIでの表示も、同じツール呼び出しを人間向けに整形したものとして理解できました。
一方で、HTTP streamを長時間購読する独自UI、Slackなどのチャネル経由のイベント差、複数ツールやHuman-in-the-loopが絡むケースまでは確認していません。特に承認待ちや失敗したtool callでは、イベント列の扱いが変わる可能性があります。ここは、今回の「正常系の1ターン」と分けて検証したほうがよさそうです。
今回の実験から得た実務上の示唆は単純です。Agentの観測を設計するときは、最終返答ではなくイベント列を先に見るべきです。TUIで気持ちよく動いたあとに、actions.requested、action.result、message.completedのどれを保存するのかを決める。そこまで確認して初めて、デモではなく運用に近い検証になります。