VercelのAIエージェントFW「eve」を導入前に調査したメモ
Vercelが出したAIエージェントフレームワークeveについて、ディレクトリ設計、Tool/Skillの違い、サンドボックス、耐久性実行などを実装前に調べた内容の整理。

最初に
公式ドキュメントとリリース情報を読み込んで、「自分のワークフローに使えそうか」を判断するための調査したので、その結果をメモとして残しておきます。
そもそも、EVEが気になったきっかけは単純で、Hermes Agentの設計を進めている中で「サブエージェント構成」「サンドボックス」「承認フロー」を自前で組むコストが気になっていたところに、Vercelがバッテリー同梱型のフレームワークを出したと知ったことです。Claude Codeのプラグイン運用やLangfuseでの観測設計と近い課題意識を持っているフレームワークに見えたので、まず仕様を頭に入れておくことにしました。
実際にローカルで動かした初回検証は、次の記事に分けています。
VercelのエージェントフレームワークEveをちょっと触ってみた https://llm-lab.dev/posts/vercel-eve-first-look/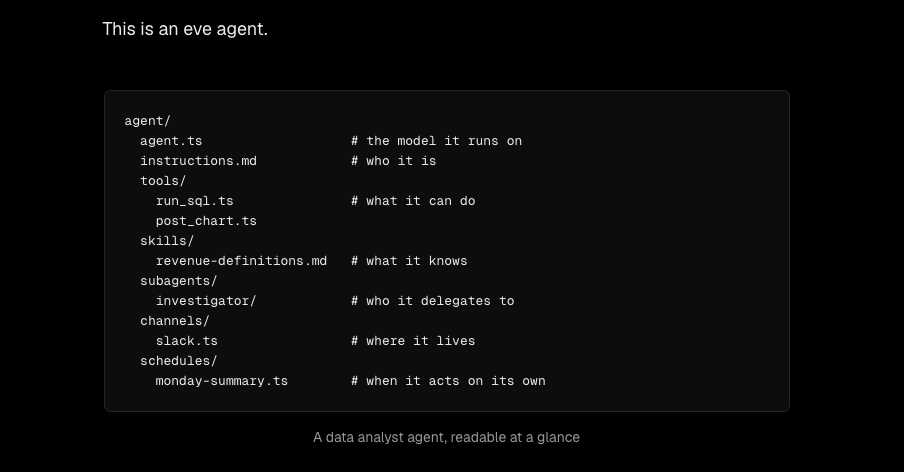
eveの基本思想:エージェントはディレクトリである
eveの核心は、 「エージェントは一つのディレクトリである(An agent is a directory)」 という設計思想にあります。agent/というディレクトリ構造そのものが、エージェントの能力とアイデンティティを定義します。
具体的には、次のようなファイル配置になります。
my-agent/
├── agent/
│ ├── agent.ts # ランタイム設定(モデル選択など)
│ ├── instructions.md # システムプロンプト
│ ├── tools/ # 実行可能なアクション
│ │ └── get_weather.ts # → get_weatherというツールになる
│ ├── skills/ # オンデマンドの知識・手順
│ │ └── summarize.md # → summarizeというスキルになる
│ ├── connections/ # 外部接続(MCPやAPI)
│ ├── channels/ # Slack、Discordなどのインターフェース
│ └── subagents/ # タスクを委譲するサブエージェント
└── evals/ # テストスイートここで重要なのは、ファイルの配置場所と名前がそのまま機能の定義になっている点です。agent/tools/get_weather.tsを置けばget_weatherというツールとして自動的に認識され、別途レジストリへ登録するようなコードは不要になります。Claude Codeのプラグイン構造やSkillsの考え方と発想は近いですが、eveはこの規約をエージェント全体のアーキテクチャに広げている印象です。
この設計が機能する理由は、開発者が「エージェントをどう動かすか」というインフラ部分から離れて、「エージェントに何をさせるか」という定義だけに集中できる点にあります。セッションの永続化、サンドボックス、承認フロー、評価といった、本来は自前で組み込む必要がある仕組みが標準で用意されているという、いわゆる「バッテリー同梱型」のアプローチです。
ToolとSkillの違いが、最初に理解すべきポイントだった
ドキュメントを読み進める中で、最初に整理が必要だったのがToolとSkillの違いです。どちらも「エージェントの能力を拡張する」という説明だけを見ると区別しにくいのですが、実体は別物です。
一言でまとめると、Toolは「実行(Action)」 であり、Skillは「知識・手順(Knowledge/Procedure)」 です。
| 観点 | Tool | Skill |
|---|---|---|
| 目的 | 実行(何かを動かす・操作する) | ガイダンス(やり方や定義を教える) |
| ファイル形式 | TypeScript(.ts) | Markdown(.md)またはTypeScript |
| 呼び出しタイミング | モデルが実行を決定した時 | 必要に応じてモデルがload_skillでロード |
| コンテキストへの影響 | 記述(description)のみが常に存在 | ロードされるまで本文は隠されている |
| 実行環境 | アプリケーションのランタイム(信頼境界の内側) | コンテキストへの追加のみ、実行機能は持たない |
Toolは、APIの呼び出しやSQLの実行といった、プログラムとして定義された具体的な動作を担います。実行環境はサンドボックスではなくアプリケーションのランタイム側にあるため、環境変数や共有ライブラリへフルアクセスできます。
一方Skillは、モデルが必要だと判断した時にだけload_skillツールを使って読み込む手順書です。すべてのスキルを常にコンテキストへ入れるのではなく、説明(description)だけを先に提示し、本文は遅延ロードする「段階的開示(Progressive Disclosure)」という設計になっています。これはAnthropicのSkills機能とほぼ同じ思想で、コンテキストウィンドウの節約という狙いも共通しています。
実務的な見極めとしては、「コードによる実行が必要ならTool」「モデルの思考をガイドする情報を与えたいならSkill」という分け方が、ドキュメント上で明示されています。DBからデータを取得するToolと、そのデータをどう解釈すべきかを説明するSkillを組み合わせる、という使い方が想定されている点も、自分たちがLangfuseでトレースを見ながらプロンプトを調整してきたやり方と地続きに感じました。
サンドボックスと信頼境界の分離
もう一つ気になっていたのが、エージェントが生成したコードをどう安全に実行するかという部分です。eveでは、信頼できる「アプリケーション実行環境(App runtime)」と、信頼できないコードが走る「サンドボックス」を明確に分離しています。
サンドボックス内からは、環境変数やアプリケーションのソースコードへアクセスできません。APIキーなどの機密情報は常にアプリケーション実行環境側に保持され、サンドボックスへは渡らない設計になっています。サンドボックスは独自の/workspaceというファイルシステムを持ち、アプリケーション本体とは隔離されています。
本番環境(Vercelデプロイ時)ではハードウェアレベルで隔離されたVercel Sandbox(microVM)上で動作し、ローカル環境ではDockerやmicrosandbox、単純なbashプロセスなど、開発者の環境に合わせたバックエンドに切り替わる仕組みです。
ネットワークアクセスが必要な場合は、認証情報をサンドボックスに直接渡さずに安全な通信を行う「資格情報ブローカー(Credential brokering)」という機能も用意されています。自前でサンドボックス環境を組むときに毎回悩む「シークレットをどこに置くか」という問題に、最初から答えが用意されている印象です。
耐久性のある実行(Durable Execution)
エージェント開発で地味に厄介なのが、長時間かかる処理や人間の承認待ちが発生したときの状態管理です。eveはこれを「セッション」「ターン」「ステップ」という3階層で管理し、ステップの境界ごとにチェックポイントを保存する仕組みを持っています。
オープンソースのWorkflow SDK(Vercelデプロイ時はVercel Workflow)をベースにした「耐久性のあるワークフロー」として各ターンが実行されるため、プロセスがクラッシュしたりタイムアウトしたりしても、最初からやり直すのではなく最後に完了したステップから再開されます。完了済みのステップは再実行されず、記録された結果がリプレイされるという仕組みです。
人間によるツール承認待ちや、時間のかかるサブエージェントの処理待ちが発生した場合は、セッションが「保留(Parked)」状態になります。保留中はワークフローがサスペンドされ、計算リソースを消費しません。数秒後でも数日後でも、必要な入力が届いた瞬間に停止箇所から再開される設計です。
これは、Claude Codeで長時間タスクを実行させたときに「セッションが切れたらどうなるか」を毎回気にしていた自分にとって、わりと刺さる機能でした。ただし、未検証の感想として書いておくと、実際にどの粒度でステップが切られるのか、コンパクション処理とチェックポイントがどう絡むのかは、ドキュメントを読んだだけでは細部まで掴めていません。
Human-in-the-loopの実装方法
承認フローについては、大きく2つのアプローチが用意されています。
1つは、ツール定義にneedsApprovalフィールドを設定する方法です。always()(毎回承認)、once()(セッション内で初回のみ)、never()(承認なし、デフォルト)というヘルパーが用意されており、入力内容に応じて承認の要否を動的に判断する条件分岐も書けます。例えば、クエリコストの推定値が一定の閾値を超えた場合だけ承認を求める、という制御が可能です。
もう1つは、ask_questionという標準組み込みツールを使い、エージェント自身がユーザーに選択肢や自由記述で回答を求める方法です。承認や質問が発生するとinput.requestedというストリームイベントが発行され、SlackアダプターなどはこれをボタンやセレクトメニューとしてネイティブUIに自動的にレンダリングします。
承認待ちの状態も、先述の耐久性のある実行の仕組みに乗っているため、プロセスの再起動やデプロイを挟んでも維持されます。メール送信や課金処理のような非冪等な操作をリプレイで二重実行してしまう事故を防ぐ目的としても、承認ゲートが機能するという説明になっています。
サブエージェントと動的スキル
発展的な機能として、サブエージェントと動的スキルにも目を通しました。
サブエージェントは、agent/subagents/<名前>/という独立したディレクトリ構造で定義します。agent.tsにdescriptionを書くことが必須で、親エージェントはこの説明を読んでどのタスクを委譲すべきか判断します。サブエージェントは親の機能を継承せず、自分専用のtools/やskills/を持ちます。なおchannels/とschedules/はルートエージェントにしか存在せず、サブエージェントではサポートされていません。
動的スキル(Dynamic Skills)は、呼び出し元のチームやテナント、ユーザー権限に応じて提供するスキルを切り替える仕組みです。defineDynamicリゾルバーの中で認証情報やチャネルのメタデータを読み取り、条件に応じてスキルを返す(あるいは何も返さない)形で実装します。人事部からの問い合わせには採用ガイドラインを、開発部からの問い合わせにはコーディング規約を出し分ける、といった例が挙げられています。これは、特定のスキルの存在自体を一般ユーザーから隠せるという点で、単なる条件分岐以上の意味を持っています。
標準で用意されている機能の幅
調査していて感じたのは、「最初から組み込まれている機能の幅が広い」ことです。ざっと並べると以下のようになります。
- 実行・ランタイム系:耐久性のある実行、サンドボックス、耐久性のある状態管理、コンパクション、Vercel AI Gatewayを介したモデルルーティング
- 人間制御・監視系:承認フロー、OpenTelemetry形式のトレーシング、Evalsによるスコアリングテスト
- 標準ツール:bash、grep、glob、readFile、writeFile、webFetch、webSearch、ask_question、load_skill、todo
- チャネル:HTTP API、Slack、Discord、Microsoft Teams、Telegram、Twilio、GitHub、Linear
- 接続:MCPやOpenAPI経由でSlack、GitHub、Snowflake、Salesforce、Notion、Linearなど
- 開発者ツール:CLI(init/dev/deploy/eval)、React/Vue/Svelte向けフロントエンドSDK、Next.js/Nuxt/SvelteKitとの統合
このリストを見ると、これまで自前で組んでいたLangfuseでのトレース管理、MCP接続、承認フローの実装が、ある程度フレームワーク側に吸収される設計になっているのが分かります。一方で、これらをどこまで使うか、どこを自分で書き換えるかという判断は、実際に手を動かしてみないと見えてこない部分です。
自分のワークフローに当てはめて考えたこと
ここまで読んで、Hermes Agentの今後の構成にどう接続できそうかを考えてみました。
サブエージェントの設計思想は、現在Hermes Agentで検討しているL1/L2/L3の責務分割と近い発想に見えます。特に、サブエージェントが親から機能を継承せず独自のtools/skillsを持つという制約は、責務の境界を明示的に切るうえで参考になりそうです。
また、承認フローについては、自前でneedsApproval相当の仕組みを実装していた部分が標準機能として提供されているため、コスト判断や書き込み操作のガードを再実装せずに済む可能性があります。ただし、これはまだ「ドキュメントを読んだ感想」の段階であり、実際にコストの閾値判定をどこまで細かく書けるか、Codexレビューのような外部ツールとの組み合わせがどうなるかは未検証です。
サンドボックスの信頼境界の分け方は、自作Botや個人開発のプロトタイプでAPIキーをどう扱うかという、地味だが毎回悩むポイントに対する一つの解として参考になります。
残っている疑問・今後試したいこと
未検証として残っている点を正直に書いておきます。
- コンパクションの挙動とチェックポイントの粒度が、実際の長時間タスクでどう振る舞うか
- MCP接続を既存のClaude Code側のMCP構成と併用できるか、競合や重複がないか
- Evalsの
t.judgeによるLLM判定が、実運用のレビュー観点とどこまで一致するか - ローカル開発(Docker/microsandboxバックエンド)と本番(Vercel Sandbox)での挙動差がどの程度出るか
次にやることとしては、まずeve initで小さいエージェントを1つ作り、Tool・Skill・承認フローを一通り動かしてみるところから始める予定です。動かしてみて詰まった点や設計判断は、別記事として改めて書きます。
まとめ
今回はeveというフレームワークについて、実装する前にドキュメントベースで概要を整理しました。「エージェントはディレクトリである」という規約に基づくファイルベースの設計、Tool(実行)とSkill(知識・手順)の役割分担、信頼境界を分けたサンドボックス、ステップ単位でチェックポイントを取る耐久性のある実行モデルが、骨格になっています。
中小企業のAI導入や個人開発のプロトタイピングでは、こうした「配管部分」を自前で組む工数がボトルネックになりやすいので、バッテリー同梱型のアプローチがどこまでハマるかは試す価値がありそうです。ただ、ここまでの内容はあくまで公式情報の整理であり、実際に動かした上での詰まりや限界はまだ分かっていません。実装したら、その続きを書きます。

